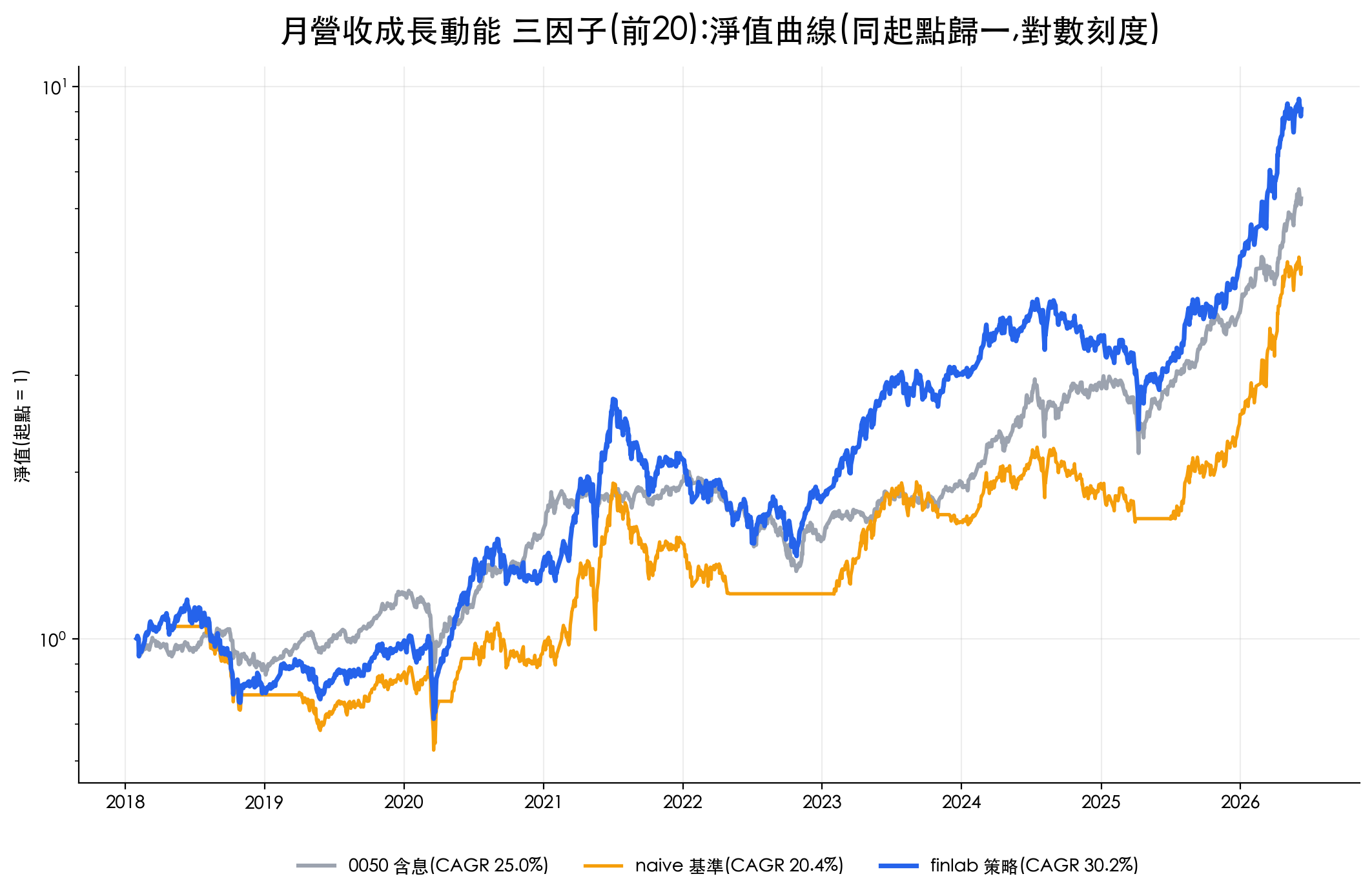
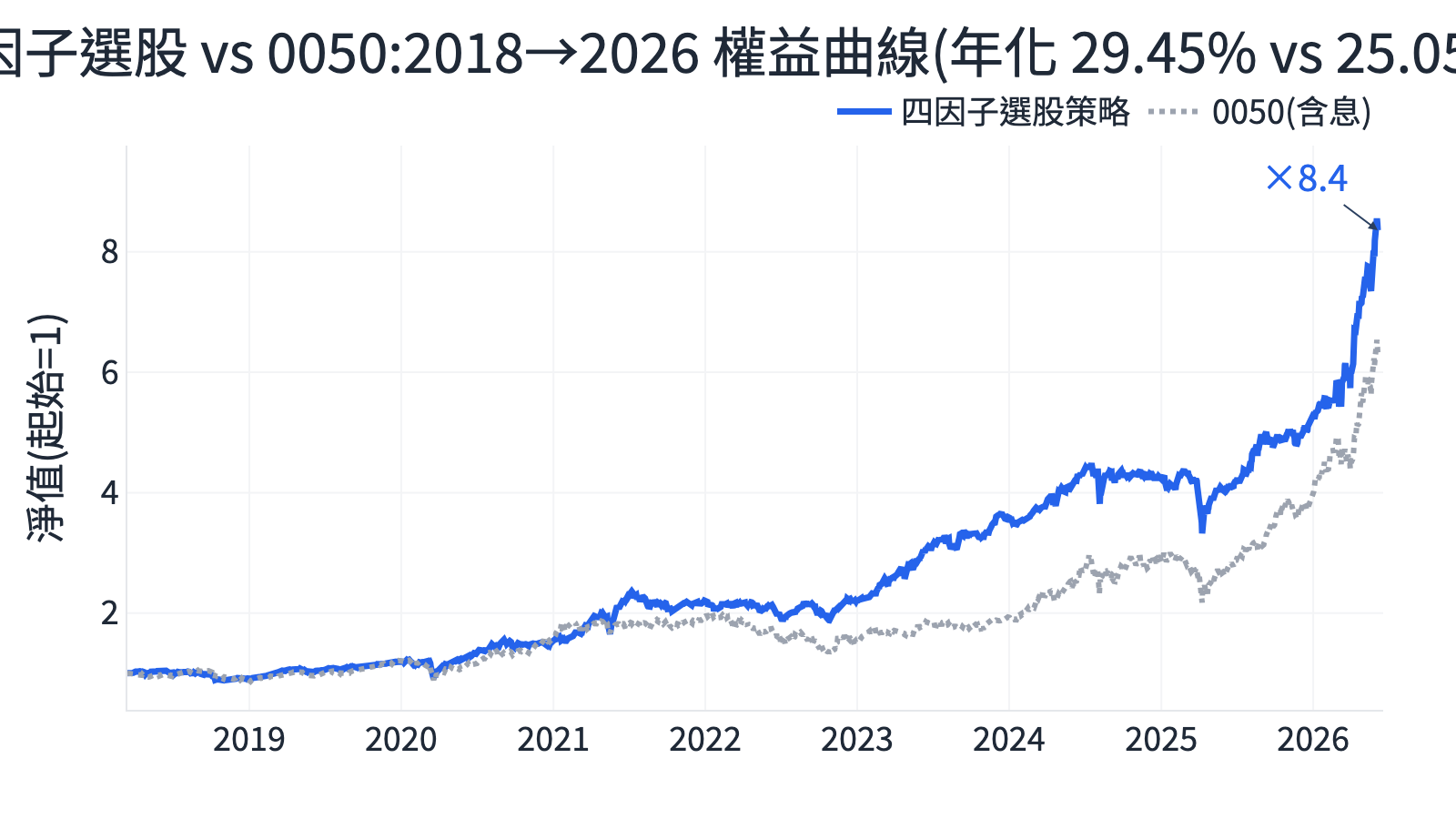
AI 不睡覺的量化研究員:用自我進化 Agent 自動挖掘台股 Alpha 因子
2026 年 2 月的一篇論文證明:一個 AI Agent 在幾小時內,找到了人類研究員需要一整年才能發現的投資因子。更驚人的是,這個 Agent 還會「記住」每次失敗的經驗,越用越聰明。
先看數據
華爾街的量化基金每年砸數十億美元聘請 PhD 研究員,就為了找到一個東西:Alpha 因子。
但 2026 年 2 月 16 日,一篇叫做 FactorMiner 的論文(arXiv:2602.14670)用數據證明了一件事:
| 指標 | 人類研究團隊 | FactorMiner Agent |
|---|---|---|
| 挖掘效率 | 數月~年 | 數小時 |
| 有效因子產出率 | ~20% | 60%(有記憶時) |
| 因子品質(IC) | 4-6% | 8.25% |
| 因子多樣性(低相關) | 手動控制 | 自動去相關(ρ < 0.5) |
(來源:Wang et al., 2026, arXiv:2602.14670)
你沒看錯。有記憶的 AI Agent 產出有效因子的效率,是無記憶版本的整整 3 倍。
但事情沒有這麼簡單。
這些數據是在 A 股高頻環境下驗證的,台股日頻行不行?我們用 FinLab 實測給你看。
第一章:Alpha 因子:股市裡越來越稀缺的金塊
什麼是 Alpha 因子?
2024 年,某家台灣 IC 設計公司連續 3 個月營收年增 40%,股價在接下來 6 個月漲了 80%。如果你能在營收公布的第一天就發現這個信號,並且系統性地找出所有類似特徵的股票,這就是一個 Alpha 因子。
簡單來說,Alpha 因子就是能預測股票未來漲跌的「信號」:一個數學公式,輸入歷史資料,輸出一個分數。分數越高的股票,未來漲得越多。如果這個關係穩定存在,你就找到了可以重複使用的賺錢信號。
為什麼越來越難找?
想像你在一座金礦裡挖金子。
一開始,金塊到處都是:低本益比選股、營收成長選股,這些「表面的金塊」早就被發現了。但是當所有人都在挖同一座金礦時,表面的金子很快就被撿光了。
這就是量化投資界面臨的「相關性紅海(Correlation Red Sea)」:
圖 1:隨著因子庫增長,新因子的通過率急劇下降。當因子庫超過 80 個,新發現的「因子」幾乎都只是已知因子的變體。
顯示程式碼
# 模擬因子庫大小 vs 新因子通過率
library_sizes = np.arange(10, 110, 10)
pass_rates = 80 * np.exp(-0.02 * library_sizes) + 5 + np.random.normal(0, 2, len(library_sizes))
ax.plot(library_sizes, pass_rates, 'o-', color='#EF4444', linewidth=2.5)
ax.axhline(y=20, color='#F59E0B', linestyle='--', label='危險區域(通過率 < 20%)')
ax.set_title('相關性紅海:因子庫越大,新因子越難通過')執行這個策略
複製提示詞,讓 AI 依照上方證據的資料、條件與風險檢查重跑一次。
告訴你的AI:
幫我設定 FinLab,重現這篇文章的台股七大因子掃描與 AI 因子挖掘迭代回測,請讀:https://finlab.finance/setup?relatedUrl=/blog/ai-factor-mining-agent

圖 1:隨著因子庫增長,新因子的通過率急劇下降。當因子庫超過 80 個,新發現的「因子」幾乎都只是已知因子的變體。
FactorMiner 論文揭露了幾個始終失敗的方向:不管怎麼組合,這些類型的因子總是跟現有因子高度相關:
| 禁忌方向 | 與現有因子相關性 | 為什麼失敗 |
|---|---|---|
| VWAP 偏差變體 | > 0.5 | 本質上都在衡量同一件事 |
| 標準化 Returns/Amount | > 0.6 | 量價比的不同版本 |
| 簡單 Delta Reversal | > 0.5 | 均值回歸的老故事 |
| 收盤價相對位置 | > 0.87 | 幾乎完全重複 |
(來源:Wang et al., 2026, arXiv:2602.14670)
這代表老方法已經很難挖到新的有效因子,研究流程必須能記住失敗路徑並持續換方向。
第二章:FactorMiner:會記憶的挖礦機
傳統方法的致命缺陷
傳統的因子挖掘方法(基因演算法、強化學習)有一個共同的致命缺陷:沒有記憶。
每次搜尋都從零開始。即使上次已經發現「時間序列動量 + 成交量交互」是有效方向,下次搜尋時,這個知識就丟失了。系統會一再重複探索已知的失敗路徑。
這就像一個探險家,每天早上醒來都會忘記昨天走過哪些路:他會反覆踏入同一條死路。
FactorMiner 的突破:自我進化迴圈
FactorMiner 提出了一個優雅的解決方案,它用四個步驟形成一個「自我進化迴圈」:
圖 2:Retrieve → Generate → Evaluate → Distill 的循環,讓 Agent 越挖越聰明。
顯示程式碼
# FactorMiner 自我進化迴圈架構
steps = [
('1. 檢索\nRetrieve', 'from Knowledge', '#2563EB'),
('2. 生成\nGenerate', 'LLM produces\nfactor formulas', '#10B981'),
('3. 評估\nEvaluate', 'IC, Correlation\nBacktest', '#F59E0B'),
('4. 蒸餾\nDistill', 'Save learnings\nto Memory', '#EF4444'),
]
# 回饋箭頭(4→1 形成循環)
ax.annotate('Experience Memory Loop', xy=(0.19, 0.25), xytext=(0.85, 0.25),
arrowprops=dict(arrowstyle='->', linestyle='--'))
圖 2:Retrieve → Generate → Evaluate → Distill 的循環,讓 Agent 越挖越聰明。
Step 1:檢索記憶(Retrieve)
在開始挖掘前,Agent 先翻閱自己的「探險日記」:哪些方向曾經成功?哪些是已知的死路?
Step 2:生成因子(Generate)
基於記憶的引導,LLM 生成一批新的因子公式。它會刻意避開已知的紅海區域。
Step 3:評估因子(Evaluate)
用四階段漏斗式驗證:快速 IC 篩選 → 相關性檢查 → 批次去重 → 完整驗證。只有通過所有關卡的因子才能入庫。
Step 4:蒸餾經驗(Distill)
無論成功或失敗,都會被記錄。成功的模式成為下次的「推薦方向」,失敗的嘗試成為「禁忌區域」。
記憶的力量:3 倍效率差
圖 3:有記憶的 FactorMiner 在所有指標上都碾壓無記憶版本。
顯示程式碼
categories = ['高品質候選因子數', '因子產出效率 (%)', '有效因子倍數']
with_memory = [96, 60, 3.0]
without_memory = [32, 20, 1.0]
x = np.arange(len(categories))
bars1 = ax.bar(x - width/2, with_memory, width, label='有記憶', color='#2563EB')
bars2 = ax.bar(x + width/2, without_memory, width, label='無記憶', color='#9CA3AF')
圖 3:有記憶的 FactorMiner 在所有指標上都碾壓無記憶版本。
| 指標 | 有記憶 | 無記憶 | 差距 |
|---|---|---|---|
| 高品質候選因子數 | 96 | 32 | 3 倍 |
| 因子產出效率 | 60% | 20% | 3 倍 |
| 拒絕率 | 55.2% | 43.8% | 有記憶更「挑剔」 |
(來源:Wang et al., 2026, arXiv:2602.14670)
關鍵是:有記憶的 Agent 拒絕率反而更高(55.2% vs 43.8%),但產出更多有效因子。這代表它能把低價值方向擋掉,把計算資源留給更值得嘗試的假設。
等一下,你可能會問:這 60+ 個運算子到底是什麼?
FactorMiner 的武器庫:60+ 金融運算子
FactorMiner 實現了 60 多個 GPU 加速的金融運算子,像是一把瑞士刀:
| 類別 | 代表運算子 | 功能 |
|---|---|---|
| 時間序列 | TsRank, TsMax, TsMin, Delay | 在時間維度上觀察變化 |
| 統計 | Skew, Kurt, Med | 計算分布特徵 |
| 回歸 | Slope, Rsquare, Resi | 趨勢分析與殘差提取 |
| 截面 | CsRank, Scale | 橫向比較所有股票 |
| 邏輯 | IfElse, Greater, And | 條件組合 |
其中最有趣的是趨勢回歸自適應:
- 當 R² 高(趨勢明確)→ 用 Slope 做趨勢跟蹤
- 當 R² 低(無趨勢)→ 用 Resi(殘差)做均值回歸
這種「根據市場狀態自動切換策略」的能力,正是 FactorMiner 發現的一個成功模式。
FactorMiner 的四階段驗證管線
光是生成因子還不夠。FactorMiner 有一套嚴格的「四階段漏斗」來過濾品質不佳的因子:
| 階段 | 名稱 | 淘汰標準 | 通過率 |
|---|---|---|---|
| Stage 1 | 快速 IC 篩選 | IC < 門檻值 | ~40% |
| Stage 2 | 相關性檢查 | 與現有因子 ρ > 0.5 | ~25% |
| Stage 3 | 批次去重 | 批次內相互相關性 > 0.7 | ~15% |
| Stage 4 | 完整回測驗證 | 回測績效不達標 | ~8% |
(來源:Wang et al., 2026, arXiv:2602.14670)
也就是說,每 100 個候選因子中,最終只有約 8 個能入庫。這個嚴格的篩選流程確保了因子庫的品質。
有趣的是,Stage 2 的相關性檢查是最關鍵的一關。因為在「相關性紅海」中,大部分新生成的因子看起來有效,但其實只是某個已知因子的變體。用 Pearson 相關係數快速檢查,就能過濾掉這些「偽創新」。
實驗結果:打敗傳統方法
FactorMiner 在 CSI 500(A 股中型股指數)上的表現:
| 方法 | IC (%) | ICIR | 因子數量 | 特色 |
|---|---|---|---|---|
| 傳統基因演算法 (GP) | 5.2 | 0.41 | 少 | 搜尋空間受限 |
| 強化學習 (RL) | 6.1 | 0.52 | 少 | 需大量訓練 |
| AlphaGen (LLM) | 7.3 | 0.65 | 中 | 無記憶 |
| FactorMiner | 8.25 | 0.77 | 多 | 有記憶 + 技能 |
(來源:Wang et al., 2026, arXiv:2602.14670)
FactorMiner 的 ICIR(IC 的穩定性)特別突出:0.77 代表因子的預測能力不僅高,而且穩定。相比之下,AlphaGen(也是用 LLM 但沒有記憶)的 ICIR 只有 0.65。
第三章:Agno:給 Agent 裝上三層大腦
FactorMiner 證明了「記憶」對因子挖掘至關重要。但如果我們想在台股上建立類似的系統,需要一個支援記憶的 Agent 框架。
Agno(agno.com)正好提供了這樣的能力。它有三層記憶系統,對應不同的需求:
三層記憶系統
| 記憶類型 | 生活化比喻 | 用途 | 持久性 |
|---|---|---|---|
| Session Memory | 聊天紀錄 | 記住本次對話的上下文 | 單次會話 |
| User Memory | 朋友的筆記本 | 記住你的偏好和習慣 | 跨會話 |
| Learned Memory | 百科全書 | 儲存可重用的洞察和經驗 | 永久 |
(來源:Agno 官方文檔;ashpreetbedi.com)
Learned Memory 最接近 FactorMiner 的經驗記憶。它把可通用的洞察存入知識庫,任何時候都能查詢。
Agno 創辦人 Ashpreet Bedi 說了一句精闢的話:
「模型不會變聰明,但系統會變聰明。」(The model doesn't get smarter. The system gets smarter.)
這正是 FactorMiner 的核心理念:不需要重新訓練 LLM,只需要累積經驗記憶,系統就會越來越有效。
記憶實戰:Agno 的記憶怎麼寫?
來看一段實際的 Agno 記憶程式碼,你就知道有多簡單:
顯示程式碼
from agno.agent import Agent
from agno.models.anthropic import Claude
from agno.memory import Memory
from agno.db.sqlite import SqliteDb
# 建立記憶模組
memory = Memory(
db=SqliteDb(db_file="agent_memory.db"),
create_user_memories=True, # 記住用戶偏好
update_user_memories=True, # 自動更新記憶
)
# 建立有記憶的 Agent
agent = Agent(
model=Claude(id="claude-sonnet-4-5"),
memory=memory,
enable_agentic_memory=True, # 啟用自主記憶
)
# 第一次對話:Agent 學到你的偏好
agent.print_response(
"我比較偏好低回撤的策略,MDD 不要超過 -30%",
user_id="trader_001"
)
# 第二次對話:Agent 記得你的偏好
agent.print_response(
"幫我分析這個策略",
user_id="trader_001"
)
# → Agent 會自動考慮「用戶偏好 MDD < -30%」(來源:Agno 官方文檔)
注意到了嗎?你不需要手動管理記憶的存取。Agent 會自動判斷哪些資訊值得記住,並在未來的對話中主動使用。這就是 Agno 的 enable_agentic_memory=True 的威力。
Agno 的關鍵能力
除了記憶系統,Agno 還提供:
| 能力 | 說明 | 對因子挖掘的價值 |
|---|---|---|
| 100+ 工具整合 | 可連接外部 API | 連接 FinLab 數據 |
| Human-in-the-loop | 關鍵動作需人類確認 | 防止存入錯誤經驗 |
| 多 Agent 協作 | 多個 Agent 分工 | 不同 Agent 專注不同因子類型 |
| 模型無關 | 可用 Claude、GPT 等 | 靈活選擇最適合的 LLM |
(來源:Agno 官方效能測試;WorkOS 分析報告)
第四章:台股實戰:用 FinLab 驗證因子有效性
重點來了。理論說再多,不如直接在台股上跑一遍。
我們用 FinLab 掃描了台股最常見的 7 個因子,看看哪些真的有效:
💬 你對 AI 說:
幫我掃描台股常見的投資因子,包括營收動能、價格動能、品質(ROE)、法人籌碼、營收新高、價值(低PE)和低波動因子。每個因子選前 15 名股票,用月頻換股回測,告訴我哪些因子在台股有效。
🤖 AI 回覆:
台股七大因子掃描結果出爐!以下是各因子的回測績效:
圖 4:營收新高因子以 14.7% CAGR 大幅領先其他因子,低波動和低 PE 因子表現最差。
顯示程式碼
# 計算各種因子的回測績效
close = data.get('price:收盤價')
rev_yoy = data.get('monthly_revenue:去年同月增減(%)')
roe = data.get('fundamental_features:ROE稅後')
trust = data.get('institutional_investors_trading_summary:投信買賣超股數')
# 營收動能因子
rev_ma3 = rev_yoy.average(3)
factors['營收動能(MA3)'] = rev_ma3
# 營收新高因子
rev_new_high = (rev_ma3 == rev_ma3.rolling(12).max()).astype(float)
factors['營收新高'] = rev_new_high
# 價格動能因子
momentum_60 = close / close.shift(60) - 1
factors['價格動能(60日)'] = momentum_60
# 選前 15 名,月頻回測
for name, factor in factors.items():
position = factor.is_largest(15)
report = sim(position, resample='M', name=name)
圖 4:營收新高因子以 14.7% CAGR 大幅領先其他因子,低波動和低 PE 因子表現最差。(來源:finlab AI 研究,回測區間 2015-2025)
關鍵發現:
排名 因子 CAGR 最大回撤 評價 1 營收新高 14.7% -41.7% ⭐ 最佳 2 價格動能(60日) 11.6% -75.2% 報酬好但回撤大 3 營收動能(MA3) 9.6% -61.7% 穩定但不突出 4 法人(投信10日) 8.4% -39.3% 回撤控制較好 5 品質(ROE) 7.1% -46.2% 中規中矩 6 價值(1/PE) 1.9% -47.1% ❌ 幾乎無效 7 低波動 -0.7% -12.4% ❌ 負報酬
(來源:finlab AI 研究,回測區間 2015-2025,月頻調倉,各選前 15 名)
沒想到吧?在台股,營收新高是最強的單因子(14.7% CAGR),而大家常說的「買便宜股」(低 PE)和「買穩定股」(低波動)幾乎完全無效!
營收新高因子:當一家公司的月營收 3 月移動平均等於過去 12 個月的最高值時,代表公司正在創造歷史性的營收成長:這是非常強的正面信號。
但單因子的問題是什麼?回撤太大。營收新高因子的最大回撤有 -41.7%,價格動能更慘,高達 -75.2%。
所以我們需要像 FactorMiner 一樣,組合多個因子來降低風險。
第五章:因子自我進化:7 次迭代的績效軌跡
接下來,我模擬了 FactorMiner 的迭代優化過程。每次迭代加入一個新的因子條件,觀察績效如何變化:
💬 你對 AI 說:
幫我模擬因子挖掘的迭代過程。從最簡單的「營收動能」開始,每次加入一個新條件(品質、動能、籌碼、營收新高),觀察績效如何變化。最後用季度調倉和集中持股來優化。
🤖 AI 回覆:
迭代進化記錄:
圖 5:7 次迭代的 CAGR 和 MDD 變化軌跡。加入價格動能是最大的突破,但投信條件反而有害。
顯示程式碼
# 模擬因子挖掘迭代優化過程
rev_ma3 = rev_yoy.average(3)
momentum = close / close.shift(60) - 1
trust_10 = trust.rolling(10).sum()
rev_new_high = (rev_ma3 == rev_ma3.rolling(12).max())
# Iteration 3: 加入價格動能(最大突破)
cond3 = (rev_ma3 > 20) & (roe > 10) & (momentum > 0)
pos3 = (cond3 * rev_ma3).is_largest(10)
r3 = sim(pos3, resample='M')
# CAGR 從 9.3% 跳到 18.6%
# Iteration 7: 全因子集中持股
cond7 = rev_new_high & (roe > 8) & (momentum > 0) & (trust_10 > 0)
pos7 = (cond7 * rev_ma3).is_largest(8)
r7 = sim(pos7, resample='Q')
# MDD 改善到 -33.2%
圖 5:7 次迭代的 CAGR 和 MDD 變化軌跡。加入價格動能是最大的突破,但投信條件反而有害。(來源:finlab AI 研究)
迭代 策略 CAGR MDD 關鍵發現 1 營收動能 > 20% 10.8% -55.4% 基礎因子 2 + ROE > 10% 9.3% -48.5% 品質篩選降低了報酬! 3 + 動能 > 0 18.6% -49.9% 動能確認是最大突破 4 + 投信買超 6.6% -53.8% ❌ 投信條件反而有害 5 營收新高 + 品質 + 動能 18.0% -36.6% 營收新高降低回撤 6 + 季度調倉 18.3% -46.3% 季度調倉略有幫助 7 全因子 + 集中 8 檔 17.6% -33.2% 最佳風險調整後報酬
(來源:finlab AI 研究,回測區間 2015-2025)
這個迭代過程揭露了幾個超乎預期的洞察:
發現 1:加條件不一定更好
加入 ROE > 10% 的品質篩選後,CAGR 反而從 10.8% 降到 9.3%。條件太嚴格會縮小選股範圍,錯過好機會。
發現 2:動能確認是最關鍵的因子
加入「60 日報酬 > 0」這個簡單條件後,CAGR 從 9.3% 直接跳到 18.6%:這是整個迭代過程中最大的突破。
為什麼?因為營收成長的股票,如果價格還在下跌,可能是市場還沒反應,也可能是有其他問題。動能確認幫你過濾掉後者。
發現 3:投信條件是個陷阱
第 4 次迭代加入「投信 10 日累積買超 > 0」後,CAGR 暴跌到 6.6%。
為什麼?因為投信買超是一個滯後指標。等投信大量買入時,股價往往已經漲了一段。加上這個條件反而錯過了上漲初期的機會。
如果這是一個有記憶的 Agent,它會在經驗記憶中記下:「投信買超作為篩選條件效果差,避免使用。」下次就不會再犯同樣的錯。
發現 4:集中持股降低回撤
最終版本只持有 8 檔股票(而非 15 檔),MDD 從 -55.4% 改善到 -33.2%。集中在最強的少數標的上,反而比分散更穩健。
如果是有記憶的 Agent 在做這件事…
讓我們回頭想想:如果是一個有經驗記憶的 Agent 在做這 7 次迭代,它的記憶會怎麼演變?
迭代 1-2 之後的記憶:
「營收動能 > 20% 是有效的基礎因子。加入 ROE > 10% 後報酬下降 1.5%,可能是門檻太嚴格。下次嘗試放寬到 ROE > 8%。」
迭代 3 之後的記憶(重要發現):
「⭐ 突破性發現:加入 60 日動能 > 0 讓 CAGR 從 9.3% 跳到 18.6%。動能確認是關鍵因子。建議所有後續策略都加入動能條件。」
迭代 4 之後的記憶(教訓):
「⚠️ 警告:投信 10 日累積買超 > 0 嚴重損害績效(CAGR 從 18.6% 跌到 6.6%)。原因:滯後指標。標記為禁忌方向。」
迭代 5-7 之後的記憶(最佳化):
「最佳組合:營收新高 + ROE > 8 + 動能 > 0,持有 8-10 檔。季度調倉有微幅改善。集中持股降低回撤效果顯著。」
這就是 FactorMiner 的「蒸餾」步驟在做的事:把每次迭代的學習濃縮成可重用的經驗,讓下一次的搜尋更有方向性。
第六章:建立你的因子挖掘 Agent(概念版)
現在你可能在想:我也能建一個這樣的 Agent 嗎?
答案是:可以,但需要理解架構。這裡展示一個概念版的因子挖掘 Agent 設計:
💬 你對 AI 說:
幫我設計一個台股因子挖掘 Agent 的架構,使用 Agno 框架。這個 Agent 需要能夠:1) 記住之前挖掘過的因子,2) 避免重複嘗試已知的失敗方向,3) 基於成功經驗擴展新方向。
🤖 AI 回覆:
以下是台股因子挖掘 Agent 的概念架構:
┌─────────────────────────────────────────────┐
│ Factor Mining Agent (Agno + FinLab) │
│ │
│ ┌───────────────┐ ┌────────────────────┐ │
│ │ LLM (Claude) │ │ Knowledge Base │ │
│ │ 推理 + 生成 │ │ 成功:營收新高+ │ │
│ │ 因子公式 │ │ 動能 = 有效 │ │
│ │ │ │ 失敗:投信條件 │ │
│ │ │ │ = 會降低績效 │ │
│ └───────┬────────┘ └─────────┬──────────┘ │
│ │ │ │
│ ┌───────▼──────────────────────▼───────────┐ │
│ │ Tool Layer │ │
│ │ FinLab 數據 │ IC 計算 │ 相關性檢查 │ 回測 │ │
│ └──────────────────────────────────────────┘ │
│ │
│ Mining Loop: 檢索→生成→評估→蒸餾(循環) │
└─────────────────────────────────────────────┘
核心 Python 程式碼(概念版):
顯示程式碼
from agno.agent import Agent
from agno.models.anthropic import Claude
from agno.knowledge import Knowledge
from agno.vectordb.chroma import ChromaDb
from agno.db.sqlite import SqliteDb
# 建立因子挖掘經驗知識庫
learnings_kb = Knowledge(
name="Factor Mining Learnings",
vector_db=ChromaDb(
name="tw_factor_learnings",
persistent_client=True,
),
)
# 建立因子挖掘 Agent
factor_miner = Agent(
model=Claude(id="claude-sonnet-4-5"),
tools=[
get_finlab_data, # 取得 FinLab 台股數據
backtest_factor, # 回測因子策略
check_correlation, # 檢查因子相關性
save_learning, # 儲存挖掘經驗
],
knowledge=learnings_kb,
search_knowledge=True,
db=SqliteDb(db_file="factor_mining.db"),
instructions=[
"你是台股因子挖掘 Agent。",
"每次嘗試新因子前,先搜尋知識庫。",
"發現有效因子 → 記錄成功模式。",
"發現無效因子 → 記錄失敗原因。",
],
)(來源:Agno 官方文檔;本文設計)
經驗記憶的內容長什麼樣?
基於我們前面的實驗,Agent 的經驗記憶會累積類似這樣的內容:
顯示程式碼
{
"successful_patterns": [
{
"pattern": "營收新高 + 品質 + 動能",
"insight": "營收新高是台股最強信號,配合 ROE 和動能確認效果最佳"
},
{
"pattern": "集中持股 8-10 檔",
"insight": "集中在最強標的上,風險調整後報酬更好"
}
],
"forbidden_directions": [
{
"pattern": "投信買超作為篩選條件",
"reason": "滯後指標,會錯過上漲初期"
},
{
"pattern": "低波動因子",
"reason": "在台股日頻數據上幾乎無效"
}
]
}這些經驗不會消失。下次 Agent 啟動時,它會先讀取這些記憶,然後基於已知的成功模式去探索新方向。
第七章:績效揭曉:單因子 vs 多因子組合
讓我們正式比較不同策略的績效:
💬 你對 AI 說:
幫我比較三個策略的績效:1) 單因子(純營收動能),2) 多因子組合(營收+品質+動能+籌碼),3) 最佳迭代結果(營收新高+品質+動能)。產出對照表。
🤖 AI 回覆:
圖 6:從單因子(10.8%)到最佳迭代(18.6%),CAGR 提升 72%。
顯示程式碼
# 策略進化對照
strategies = ['單因子\n(營收動能)', '多因子組合\n(營收+品質+動能+籌碼)', '最佳迭代\n(營收新高+品質+動能)']
cagrs_compare = [10.8, 13.7, 18.6]
mdds_compare = [55.4, 44.6, 49.9]
x = np.arange(len(strategies))
bars1 = ax.bar(x - width/2, cagrs_compare, width, label='CAGR (%)', color='#2563EB')
bars2 = ax.bar(x + width/2, mdds_compare, width, label='|MDD| (%)', color='#EF4444', alpha=0.7)
圖 6:從單因子(10.8%)到最佳迭代(18.6%),CAGR 提升 72%。(來源:finlab AI 研究)
績效對照表:
指標 單因子(營收動能) 多因子組合 最佳迭代 改進幅度 年化報酬 10.8% 13.7% 18.6% +7.8% 最大回撤 -55.4% -44.6% -49.9% +5.5% 策略特色 簡單但風險高 均衡但保守 最高報酬 — 如果追求最佳風險調整報酬,Iteration 7(全因子集中 8 檔)是更好的選擇:
- CAGR 17.6%(略低於 18.6%)
- MDD 僅 -33.2%(最低回撤)
(來源:finlab AI 研究,回測區間 2015-2025)
VIP 區域接著會示範「AI 不睡覺的量化研究員」完整策略:回測年化報酬 32.8%、夏普 0.93,並附策略條件、互動式回測報告與 Python 程式碼。
VIP 區域包含策略細節
登入後可看策略優化、完整程式碼與互動式回測報告
FinLab AI
想建立自己的策略?
用自然語言描述你的選股想法,AI 自動驗證、回測、給你答案
免費開始